Day 9 Kaggle's 30 Days of ML

Course Step 3 of ML learning tutorial.
Use panda to deal with data set.
# list out all the column var
data_set.columns
# get one feature (column)
data_set.feature_name
data_set.feature_name['feature_name']
# get features
data_set[list_of_features]
# drop NA data
data_set.dropna(axis = 0)

Build the model
steps:

Use scikit-learn library(sklearn).

Here, X is the sub data_set we created by choosing several features.
random_state makes sure that the random state will be the same for each run.
Then, we use the model to predict the price comparing to the actual data.
Course Step 3 of ML learning tutorial.
Model validation
Use Mean Absolute Error(MAE):
Add each error and divide by num of error. (error = actual - predicted)

The Problem with "In-Sample" Scores:
If we use the training data to test, the result will definely be accurate since the model derives the pattern from the training data. However, we need to the model to apply on other situations, so we should use new data to examine model accuracy.
The solution is to seperate the data set into two parts: one part for training and one part for validation.
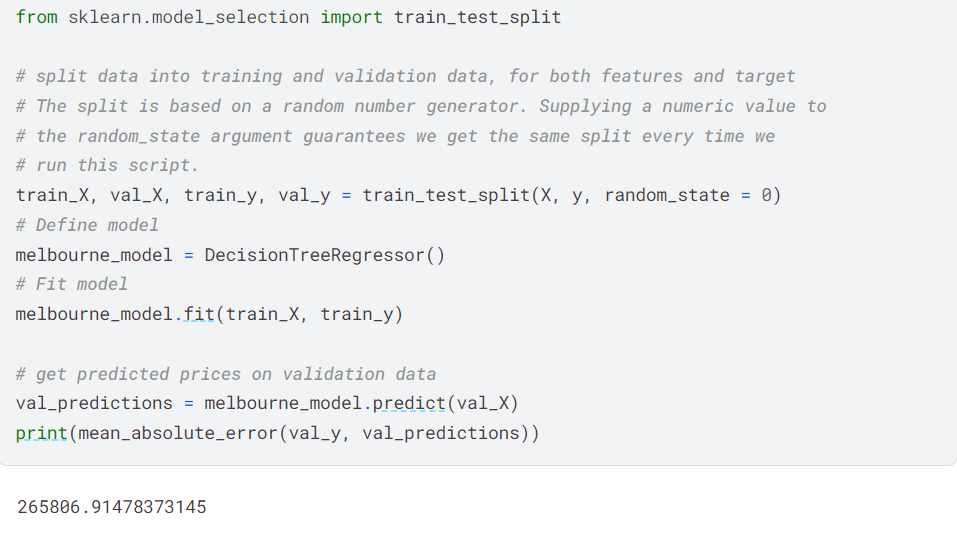
Here, we import the built-in func in sklearn train_test_split.
(we can use arg test_size = 0.1 to set 90% of the data for training, and the rest for validation.)
This func returns 4 var, X is the features, y is the target.
train_X is the features we used for training, and train_y is the target we used for it.
val_X and val_y are used for validation.
After doing the training, we examine the data validaiton using mae. The mae is high here, so this model is not accurate.