Day 14 Part 1 Kaggle's 30 Days of ML

Course Step 6 of Intermediate Machine Learning.
Gradient Boosting
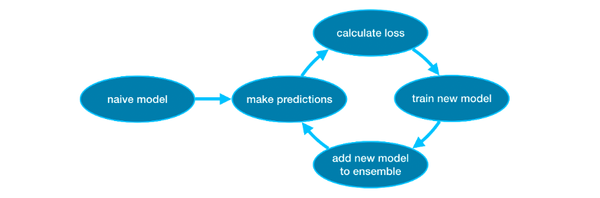
Basically, it is a process to generate an ensemble by gradually adding model into it.
We build a model and do the prediction and validation, then adding a new model into it and repeat.
Basic Code:
XGBoost

stands for
extreme gradient boosting.

Some Parameters:
n_estimator: Same as n_estimator in DecisionTree.
Too low a value causes underfitting;
Too high a value causes overfitting.
Typical values range from 100-1000.
learning_rate:
we multiply the predictions from each model by a small number (known as the learning rate) before adding them in.
So, we can set a higher value for n_estimator without overfitting.
As default, XGBoost sets learning_rate=0.1.
A small learning rate and large number of estimators will yield more accurate XGBoost models, though it will also take the model longer to train.
early_stopping_rounds:
A way to automatically find the ideal value for n_estimators.
Use it as parameter for fit.
With it, we not longer need to worry about larger n_estimators will cause overfitting.
Setting early_stopping_rounds=5 is a reasonable choice.
Also need to set aside some data for calculating the validation scores - this is done by setting the eval_set parameter.
n_jobs:
Allow us to assign parallel task to build model fater.
It's common to set the parameter n_jobs equal to the number of cores on your machine. On smaller datasets, this won't help.