Day 13 Part 2 Kaggle's 30 Days of ML

Course Step 4 of Intermediate Machine Learning.
cross-validation:

The idea is to seperate the data into 5 pieces, as 5 folds.
In each fold, we use the blue data for validation, and the rest for training.
It has a more accurate model quality measurement.
For small data: doing computation is fast, so using cross-validation is better.
For large data: normal validation would be efficient. If the model takes a couple minutes or less to run, it's probably worth switching to cross-validation.
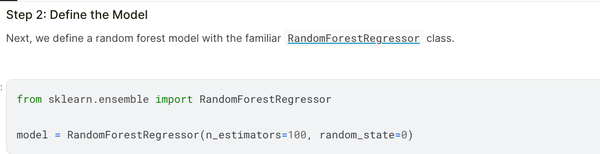
Use pipeline for cross validation: