Day 10 Kaggle's 30 Days of ML

Course Step 5 of machine learning.
Overfitting:
Generally, it means we make the model to0 fit to the training data, so the model will perform worth when using new data to do the prediction.
Under the topic of Decision Tree Model, if we make the level so deep, it will have a high probability causing overfitting.
Underfitting:
Opposite to overfitting, underfitting in general means that the model cannot capture distinctions and patterns in the training data, and performs bad with it.
Under the topic of Decision Tree Model, if we make the level so shallow, it will have a high probability causing underfitting.
Note: if we split part of the training data to become the validation data, and our model is overfitting, the result of prediction might be not accurate. Thus, it is important to use new data for test.
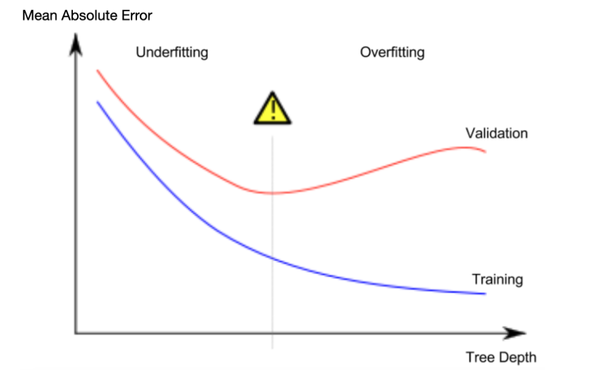
We need to find a sweet spot.
The techenique is to make a func for mae calculation and use loop for comparison.

Course Step 6 of machine learning.
Use Bagging:
The idea of bagging is related to random forest tree model.
Suppose we have a data set of 4 features and 1000 samples, instead of building one modle on it, we can use bagging to build multiple models.
We create several other data sets with the same number of features and size, then we randomly pick samples from the original data set, so there will be repeate sample and unchosen sample, which are totally fine.
Then, we build model on each data set, and caculate the mean probability result of those models or use max voting to choose a result class.
Random Forest Tree Model:
This is an assemble of multiple Decision Tree Models.
We create sub data set with sub-features and pick sample randomly until have the same number as the original data set. Then, we build models on each data set and combine the results.
Note: the not selected samples are called out-of-bag samples. We can use these out-of-bag samples as validation samples for test, and the error is called "oob error".
Parameters:
n_estimators: number of subtrees
k: number of features for each tree (normally root square n, n is the total num of features)
