Daily LeetCode #4

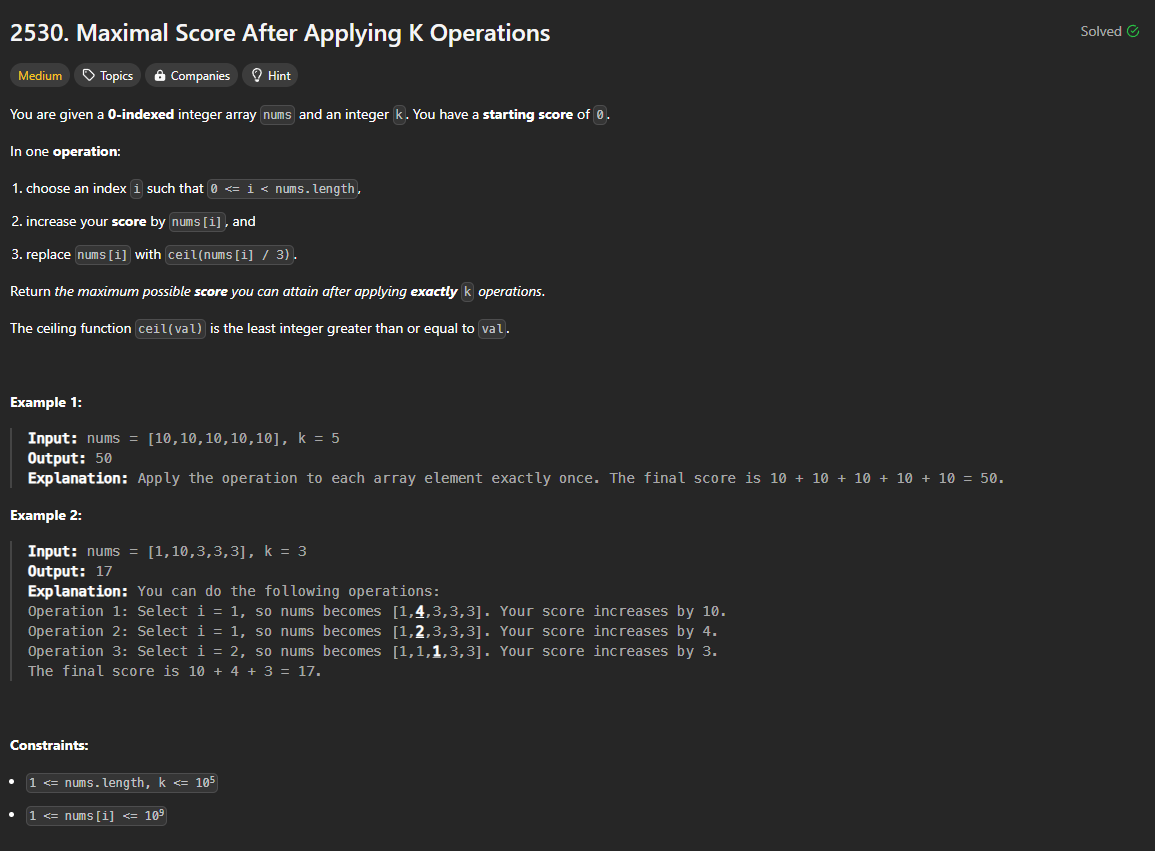
We need to continuously select the largest num in the list, so Priority Queue is a good choice.
We also need to keep track of index of each num in the original list, since we need to modify one after adding into the score.
Steps:
- create a max pq that stores
int[]in form of(num, index) - put all the nums in the list into pq
- for each operation, dequeue from pq, add num into score, modify the
num, and then add num with itsindexback to pq again
class Solution {
public long maxKelements(int[] nums, int k) {
// define pq to store element in form of (num, index)
PriorityQueue<long[]> pq = new PriorityQueue<>((a,b) -> Long.compare(b[0], a[0]));
// initialize pq by adding all elements from nums
for(int i = 0; i < nums.length; i++) {
pq.offer(new long[]{nums[i], i});
}
// use n to record operation times
int n = 0;
long res = 0;
while(n < k) {
long[] current = pq.poll();
long num = current[0];
long index = current[1];
res += num;
// ceiling logic
num = (num % 3 == 0) ? num / 3 : num / 3 + 1;
pq.offer(new long[]{num, index});
n++;
}
return res;
}
}Notes:
- need to use
longsince we need to return along - use
(a,b) -> Long.compare(b[0], a[0])instead ofb[0] - a[0], because it might lead to overflow
Time Complexity: O(nlogn) [pq opertation O(logn)]
Space Complexity: O(n) [use the pq]
Some notes on first 10 problems from SQL 50.
https://leetcode.com/problems/invalid-tweets/description/?envType=study-plan-v2&envId=top-sql-50
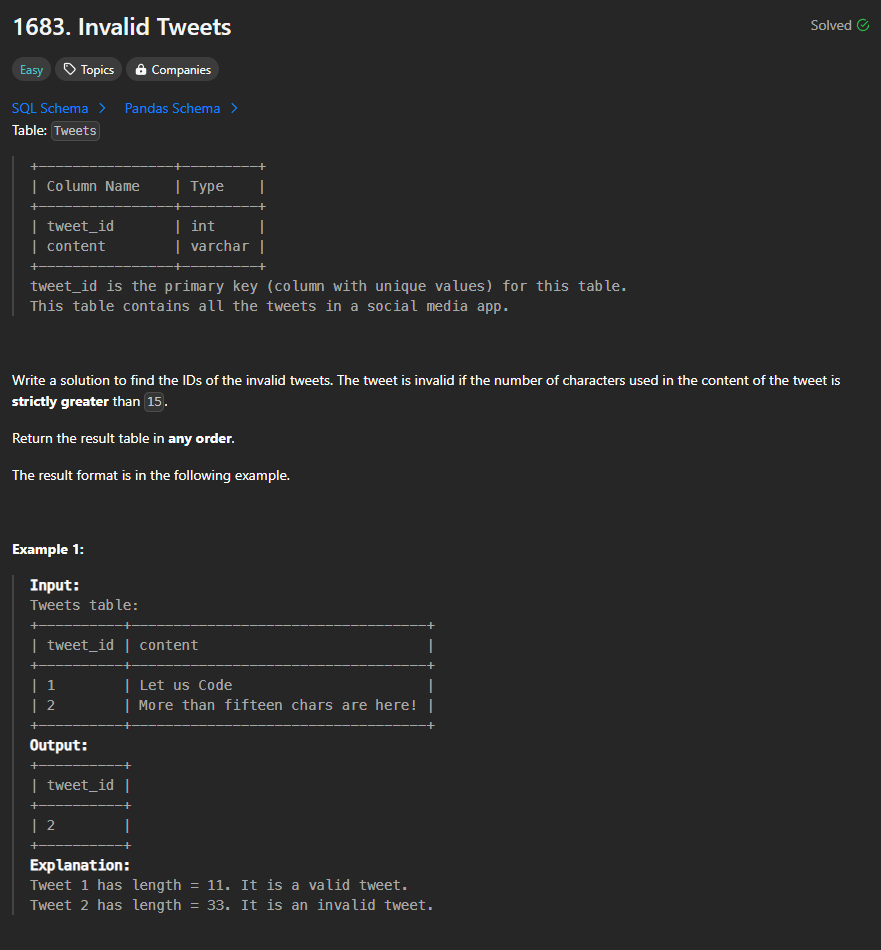
I learned one thing which was taught in class:
Use LENGTH(attribute) returns the number of characters in a given string.
SELECT tweet_id
FROM Tweets
WHERE LENGTH(tweet_id) > 0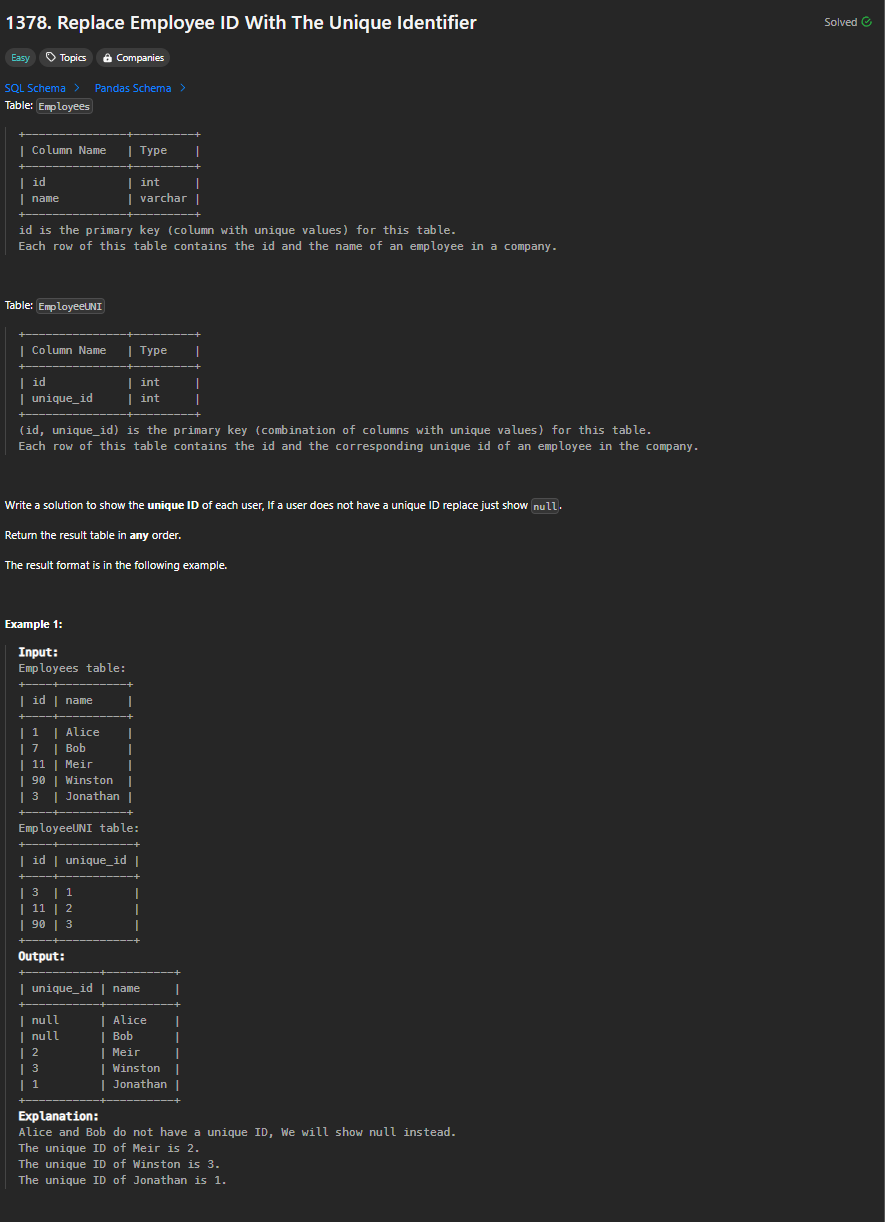
REVIEW:
A LEFT OUTER JOIN B will mark record without attributes in B to NULL
While using for example here WHERE A.id = B.id would discard those records with NULL in the above case.
SELECT unique_id, name
FROM Employees LEFT OUTER JOIN EmployeeUNI ON Employees.id = EmployeeUNI.id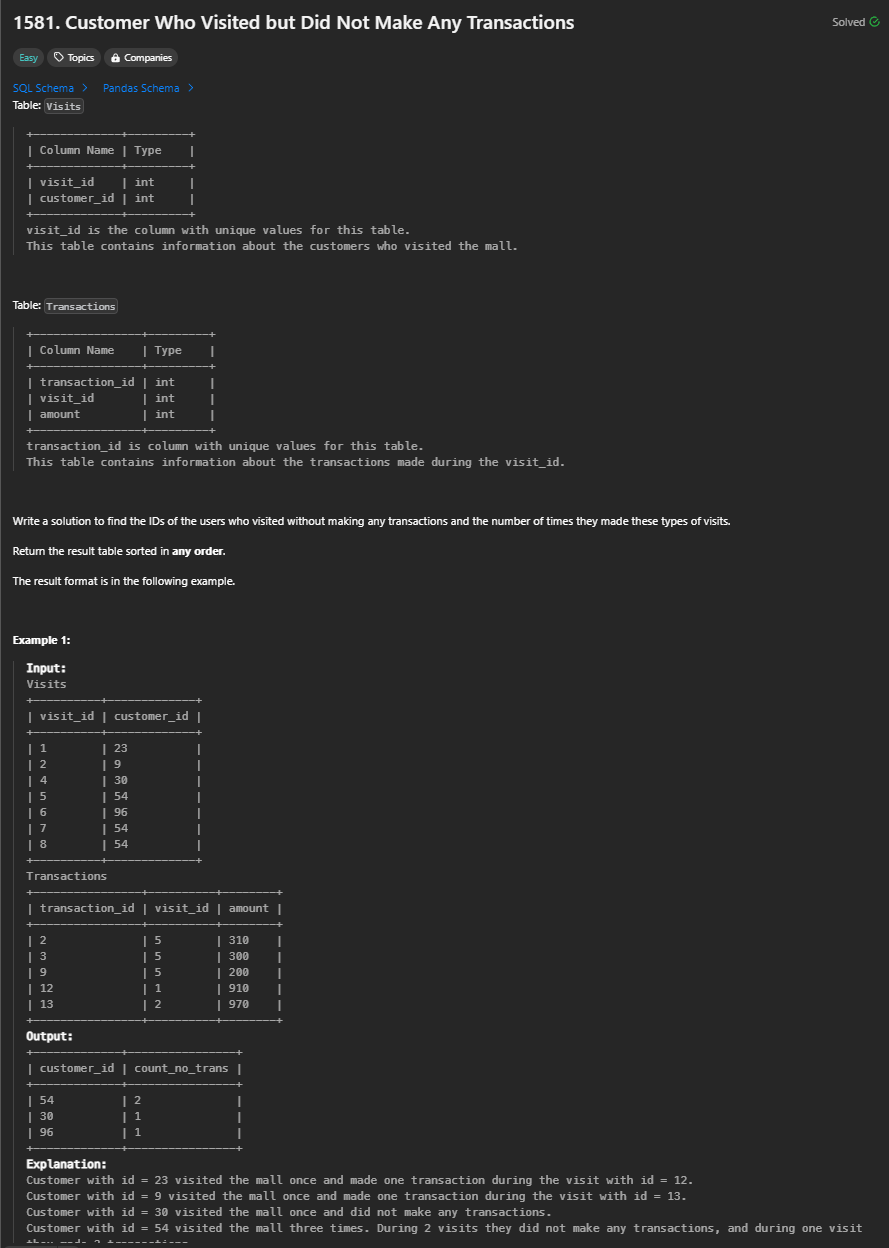
REVEIW:
Need to use subquery to determine the set of visit_id with no trasactions, and then group those records to get num.
SELECT customer_id, count(*) AS count_no_trans
FROM Visits as V
WHERE V.visit_id NOT IN (SELECT DISTINCT visit_id
FROM Transactions)
GROUP BY V.customer_id;
Some mistakes I made:
- the syntax is
NOT IN butnotIS NOT IN - only need to use
Visitstable in the main query, otherwise will lead to Cartesian join of two tables leading more unncessary records
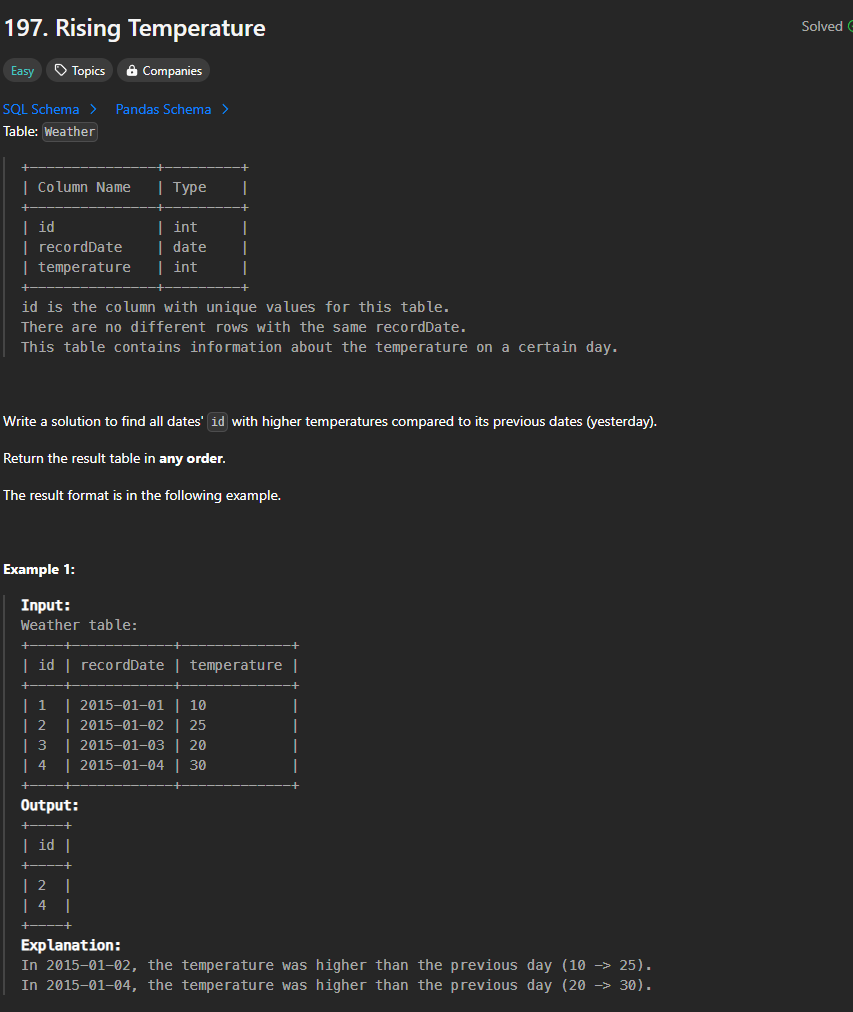
REVIEW:
Need to do Cartesian product between the Weather table and itself.
Remember to assign name to each table.
Function DATEDIFF() is used on Date type.
SELECT today.id
FROM Weather AS today JOIN Weather AS yesterday
WHERE DATEDIFF(today.recordDate, yesterday.recordDate) = 1
AND today.temperature > yesterday.temperature
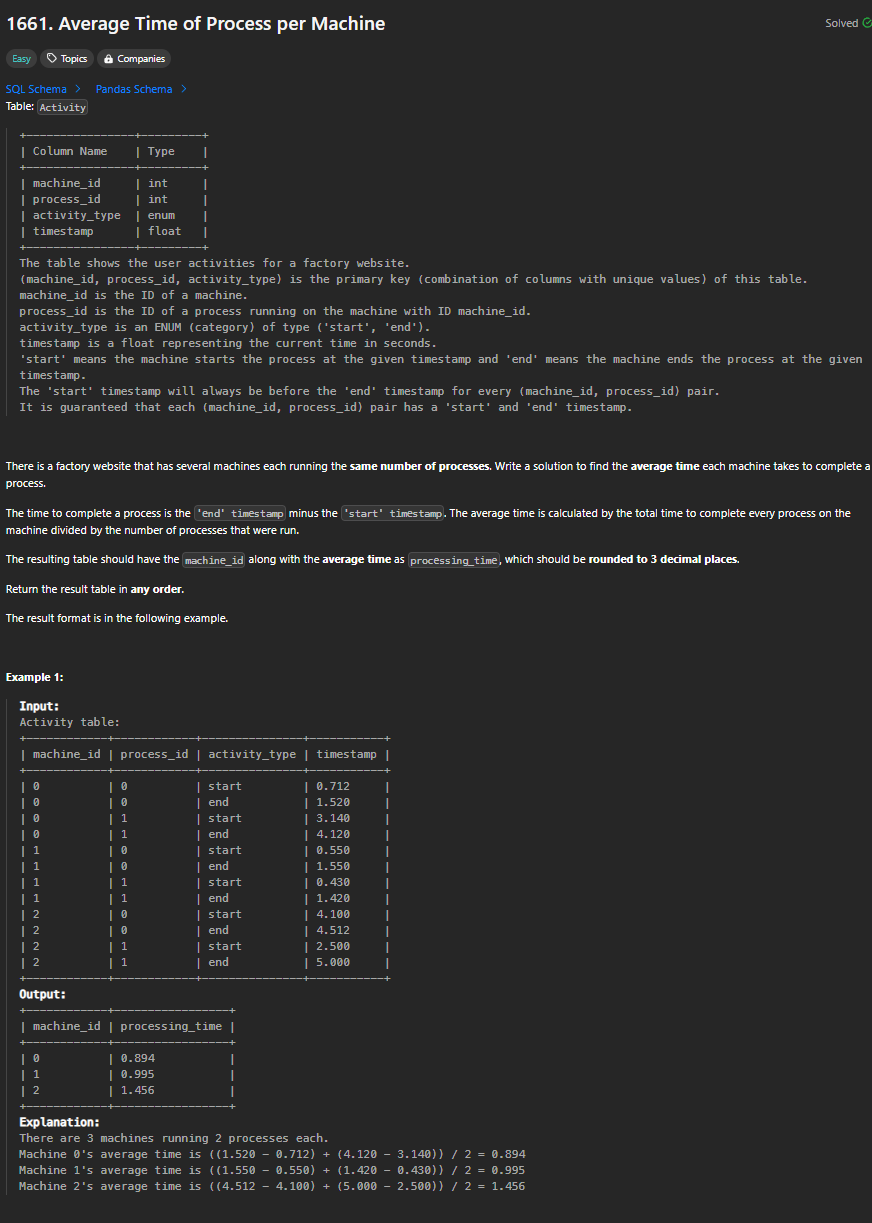
NOTE:
Do Cartesian product between Activity and itself.
Matching the record with the same machine_id and process_id but with different activity_type.
Caculate the time span, then group by machine_id to get average time.
round(float, n) rounds a float to n decimal places.
SELECT start.machine_id, round(avg(end.timestamp - start.timestamp), 3) AS processing_time
FROM Activity AS start JOIN Activity AS end
WHERE start.machine_id = end.machine_id
AND start.process_id = end.process_id
AND start.activity_type = "start"
AND end.activity_type = "end"
GROUP BY start.machine_id